
参考にした資料は思いつく限り一番最後に載せておきます。
※Transformerの論文はこのリンク先のPDFというところをクリック
この記事は未完成です。Transformerを理解するのに大事だと思うことから少しずつ書き足していきます。
解説
Transformerの論文に載っている図(Figure 1)を少し見てきて欲しいのですが、論文の図だと分かりませんが、最重要なこととして、このモデルを情報(単語もしくはトークン)は下の図のように流れます。
これをまずは理解してほしいです。
解説すると、下の図の左側はエンコーダーを表しています。
まずはエンコーダーについて解説しますが、論文の図で入力はInputsとだけ書いてありますが、正確にはこれは単語のIDがいくつか連なっているものです。
下の画像の例でいうと、「今日」の単語ID、「は」の単語ID、「良い」の単語ID、「天気」の単語ID、「だ」の単語IDが一斉に入力されます。
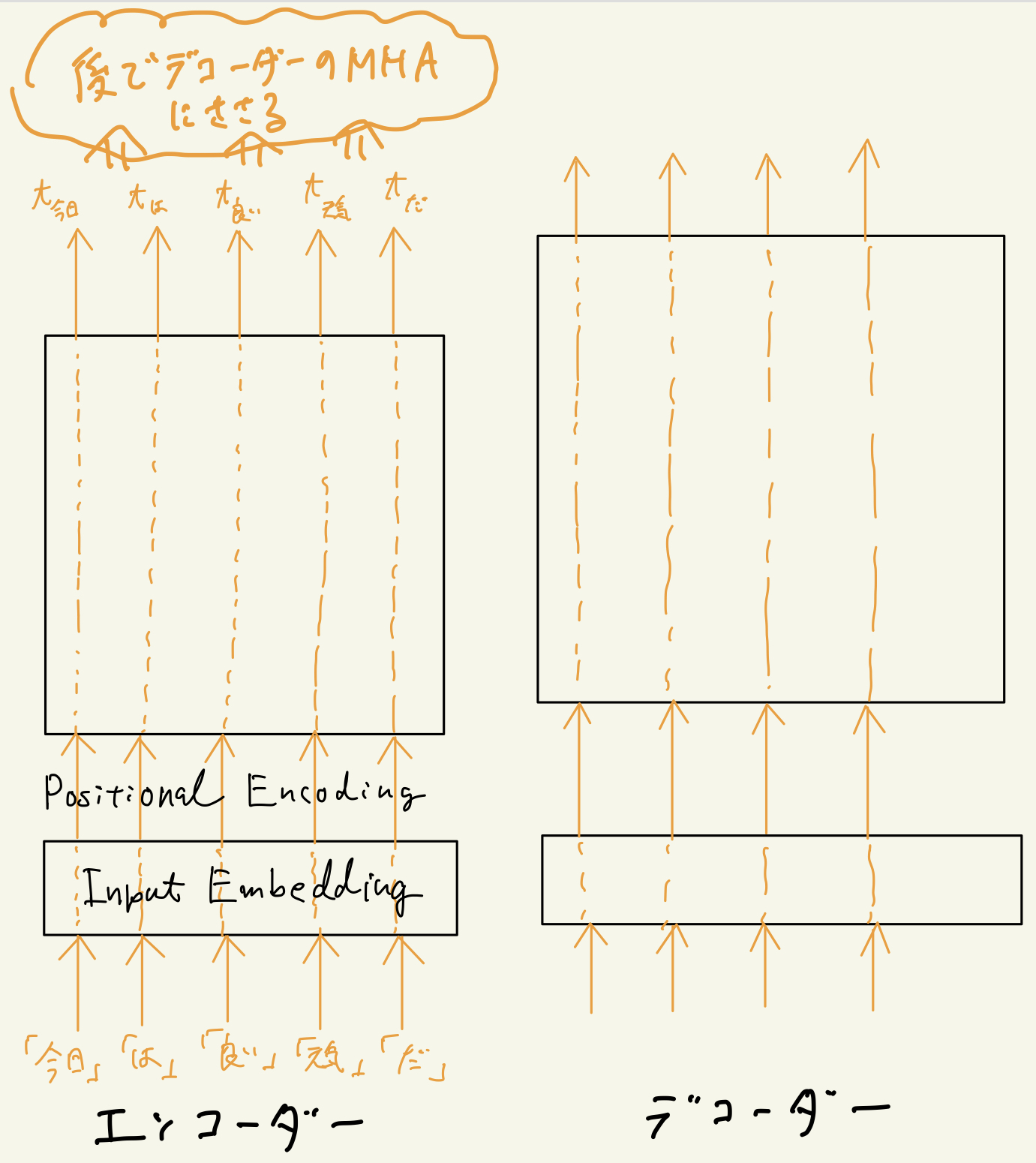
そして、まずは一般的なEmbedding層(上の図ではInput Embeddingのところ)にそれらの単語IDが入力され、それぞれ論文で言うところのd_model次元の単語埋め込みベクトルに変換されます。
つまり、Input Embeddingを通過した時点でd_model次元のベクトルが入力した単語数生成されているわけです。
※Positional Encodingは、おいおいこの記事に説明を追加しますが、簡単に説明しておくとPositional Encodingを通過してもd_model次元のベクトルが単語数分、レイヤを流れている状況は変わりません。
そしてMulti-Head Attention(MHA)やらFeed Forwardやらが行われるブロックを通過するわけですが、いちばん大事なことは、これらのブロックを通過した後も流れている情報は相変わらずで、d_model次元のベクトルが単語数分出力されます。
そして上の図のように、エンコーダーの出力は入力された単語に対応するd_model次元のベクトルとなります。単語を3個入力して出力が5個になったりすることはなく入力した単語数と同じ数だけベクトルが出力されます。
簡単なイメージで説明すると、串がいくつか刺さった蒲焼を想像すると良いでしょう。
とりあえず、今日はここまで。
-5

